Apple’s M3 family benefits from new GPU features

Apps and games that utilize the Metal API target specific functions of Apple Silicon GPUs, which get even better with significant improvements to parallel processes in M3 and A17 Pro. Here’s how it works.
Apple released a developer talk on these new Apple Silicon GPU features detailing exactly what’s happening to achieve improved results. The video goes into great technical detail, but provides enough to explain in basic terms.
Developers building apps with the Metal API don’t need to make any changes to their apps to see performance improvements with M3 and A17 Pro. These chipsets utilize Dynamic Caching, hardware-accelerated ray tracing, and hardware-accelerated mesh mapping to make the GPU more performant than ever.
Dynamic shader core memory
Dynamic Caching is made possible thanks to a next-generation shader core. When utilizing the latest GPU cores in A17 Pro and M3, these shaders can run in parallel much more efficiently than before, massively improving output performance.

Dotted lines represent wasted register memory
Normally, the GPU is only able to allocate register memory based on the highest bandwidth process within an executed action for the duration of that action. Therefore, if one part of an action requires significantly more register memory than the rest, the action will utilize much more register memory for a given process.
Dynamic Caching allows the GPU to allocate exactly the right amount of register memory for every action it is taking. The previously unavailable register memory is freed, allowing for many more shader tasks to occur in parallel.
Flexible on-chip memory
Previously, on-chip memory would have fixed memory allocation for register, threadgroup, and tile memory with a buffer cache. That meant significant portions of memory went unused if an action utilized more of one type of memory than another.
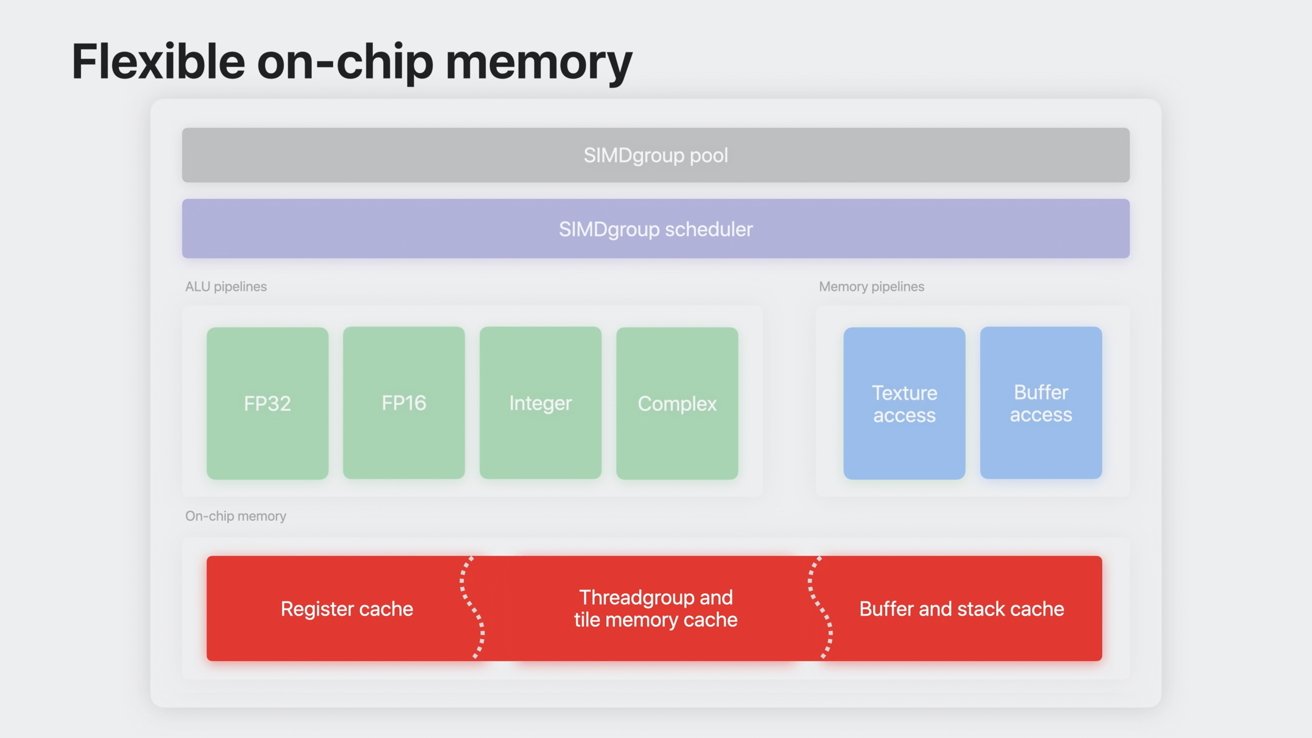
The entire on-chip memory can be used as cache
With flexible on-chip memory, all of the on-chip memory is a cache that can be utilized for any memory type. So, an action that heavily relies on threadgroup memory can utilize the entire span of the on-chip memory, and even overflow actions into main memory.
The shader core dynamically adjusts on-chip memory occupancy to maximize performance. That means developers can spend less time optimizing occupancy.
Shader core’s high-performance ALU pipelines
Apple recommends developers execute FP16 math in their programs, but the high-performance ALUs execute different combinations of integer, FP32, and FP16 in parallel. Instructions are executed across different actions performed in parallel, which means ALU utilization is improved with higher occupancy.

Increased parallel operations with high-performance ALU pipelines
Basically, if different actions contain the same FP32 or FP16 instructions that would be executed at different points in time, the executions can be overlapped to increase parallelism.
Hardware-accelerated graphics pipelines
Hardware-accelerated ray tracing makes the process much faster, taking the vital intersection calculations out of the GPU function. Since there’s hardware taking care of a portion of the calculations, it allows more operations to occur in parallel, thus speeding up ray tracing with a hardware component.
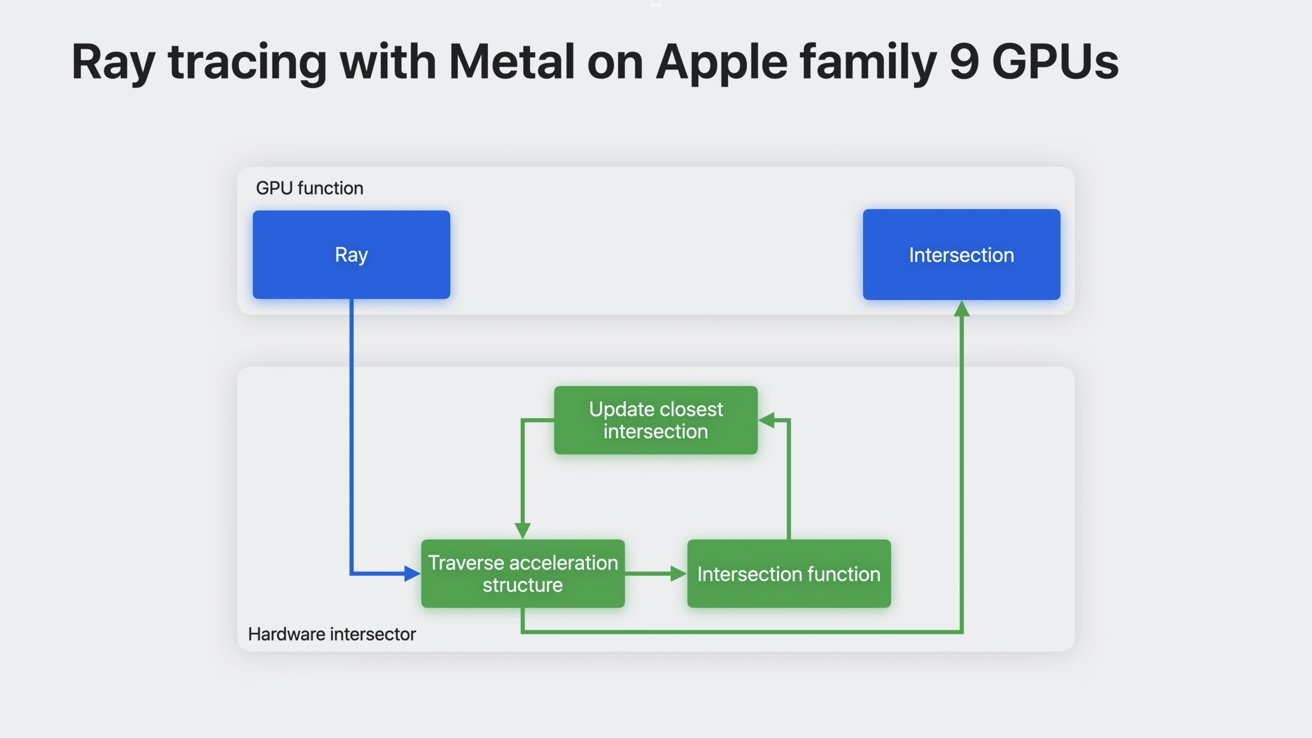
Hardware-acceleration takes over from on-chip processes
Hardware-accelerated mesh shading utilizes a similar method. It takes the middle of the geometric calculations pipeline and passes it to a dedicated unit, thus allowing more parallel operations.
These are complex systems that can’t be broken down into a few paragraphs. We recommend watching the video to get all the details with one thing in mind — A17 Pro and M3 focus on computing parallelism to speed up tasks.

