Join leaders in San Francisco on January 10 for an exclusive night of networking, insights, and conversation. Request an invite here.
Writer, a three-year-old San Francisco-based startup which raised $100 million in September 2023 to bring its proprietary, enterprise-focused large language models to more companies, doesn’t hit the headlines as often as OpenAI, Anthropic or Meta — or even as much as hot LLM startups like France-based Mistral AI.
But Writer’s family of in-house LLMs, called Palmyra, may well be the little AI models that could, at least when it comes to enterprise use cases. Companies including Accenture, Vanguard, Hubspot and Pinterest are Writer clients, using the company’s creativity and productivity platform powered by Palmyra models.
Stanford HAI‘s Center for Research on Foundation Models added new models to their benchmarking last month and developed a new benchmark, called HELM Lite, that incorporates in-context learning. For LLMs, in-context learning means learning a new task from a small set of examples presented within the prompt at the time of inference.
Writer’s LLMs performed ‘unexpectedly’ well on AI benchmark
While GPT-4 topped the leaderboard on the new benchmark, Palmyra’s X V2 and X V3 models “perhaps unexpectedly” performed well “despite being smaller models,” posted Percy Liang, director of the Stanford Center for Research on Foundation Models.
VB Event
The AI Impact Tour
Getting to an AI Governance Blueprint – Request an invite for the Jan 10 event.
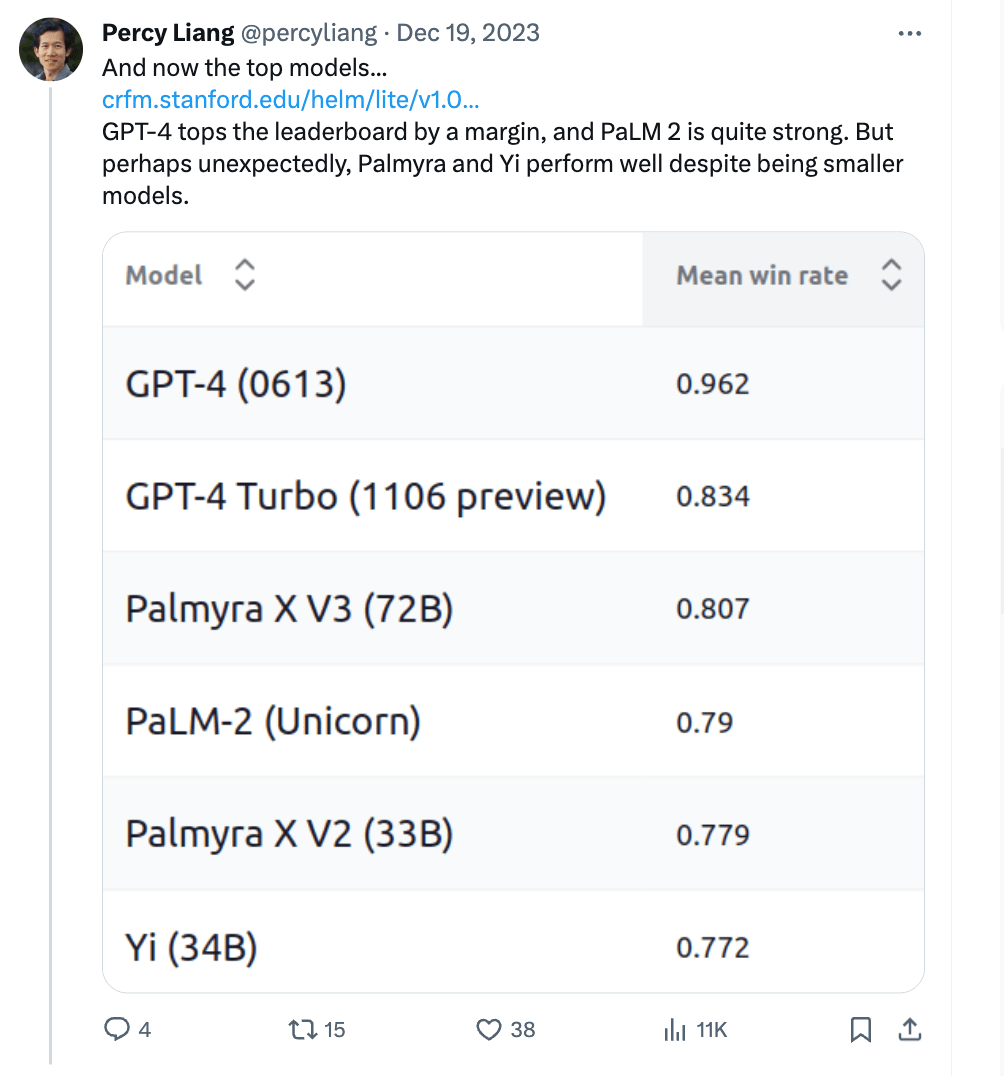
Palmyra also performed particularly well — landing in first place — in the area of machine translation. Writer CEO May Habib said in a LinkedIn post: “Palmyra X from Writer is doing EVEN BETTER than the classic benchmark. We aren’t just the top model in the MMLU benchmark, but the top model in production overall — close second only to the GPT-4 previews that were analyzed. And across translation benchmarks — a NEW test — we’re #1.”
Enterprises need to build using economically viable models
In an interview with VentureBeat, Habib said that enterprises would be hard-pressed to run a model like GPT-4, trained on 1.2 trillion tokens, in their own environments for an economically viable cost. “Generative AI use cases [in 2024] are now actually going to have to make economic sense,” she said.
She also maintained that enterprises are building use cases on a GPT model and then “two or three months later the prompts don’t really work anymore because the model has been distilled, because their own serving costs are so high.” She pointed to Stanford HAI’s HELM Lite benchmark leaderboard and maintained that GPT-4 (0613) is rate-limited, so “it is going to be distilled,” while GPT-Turbo is “just a preview, we have no idea what their plans are for this model.”
Habib added that she believes Stanford HAI’s benchmarking efforts are “closest to real enterprise use cases and real enterprise practitioners,” rather than leaderboards from platforms like Hugging Face. “Their scenarios are much closer to actual utilization,” she said.
Writer, which began as a tool for marketing teams in mid-2020, was previously a company called Qordoba, founded in 2015 by co-founders Habib and Waseem AlShikh. In February 2023, Writer launched Palmyra-Small with 128 million parameters, Palmyra-Base with 5 billion parameters, and Palmyra-Large with 20 billion parameters. With an eye on an enterprise play, Writer announced Knowledge Graph in May 2023, which allows companies to connect business data sources to Palmyra and allows customers to self-host models based on Palmyra.
“When we say full stack, we mean that it’s the model plus a built-in RAG solution,” said Habib. “AI guardrails on the application layer and the built-in RAG solution is so important because what folks are really sick and tired of is needing to send all their data to an embeddings model, and then that data comes back, then it goes to a vector database.” She pointed to Writer’s new launch of a graph-based approach to RAG to build digital assistants grounded in a customer’s data.
For LLMs, size matters
Habib said she has always had a contrarian view that enterprises need smaller models with a strong focus on curated training data and updated datasets. VentureBeat asked Habib about a recent LinkedIn from Wharton professor Ethan Mollick that cited a paper about BloombergGPT and said “the smartest generalist frontier models beat specialized models in specialized topics. Your special proprietary data may be less useful than you think in the world of LLMs.”
In response, she pointed out that the HELM Lite leaderboard had medical LLM models beating out GPT-4. In any case, “once you are beyond the state of the art threshold, things like inference and cost matter to enterprises too,” she said. “A specialized model will be easier to manage and cheaper to run.”
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.

