
As the AI landscape has expanded to include dozens of distinct large language models (LLMs), debates over which model provides the “best” answers for any given prompt have also proliferated (Ars has even delved into these kinds of debates a few times in recent months). For those looking for a more rigorous way of comparing various models, the folks over at the Large Model Systems Organization (LMSys) have set up Chatbot Arena, a platform for generating Elo-style rankings for LLMs based on a crowdsourced blind-testing website.
Chatbot Arena users can enter any prompt they can think of into the site’s form to see side-by-side responses from two randomly selected models. The identity of each model is initially hidden, and results are voided if the model reveals its identity in the response itself.
The user then gets to pick which model provided what they evaluate to be the “better” result, with additional options for a “tie” or “both are bad.” Only after providing a pairwise ranking does the user get to see which models they were judging, though a separate “side-by-side” section of the site lets users pick two specific models to differentiate (without the ability to contribute a vote on the result).
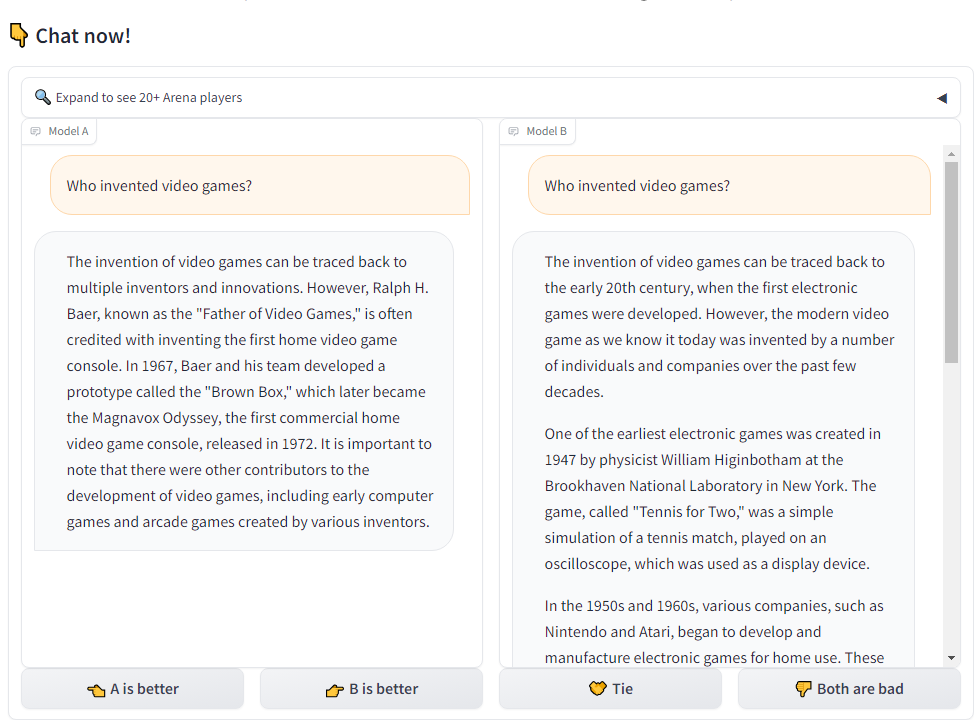
Since its public launch back in May, LMSys says it has gathered over 130,000 blind pairwise ratings across 45 different models (as of early December). Those numbers seem poised to enhance quickly after a recent positive review from OpenAI’s Andrej Karpathy that has already led to what LMSys describes as “a super stress assess” for its servers.
Chatbot Arena’s thousands of pairwise ratings are crunched through a Bradley-Terry model, which uses random sampling to produce an Elo-style rating estimating which model is most likely to win in direct competition against any other. Interested parties can also dig into the raw data of tens of thousands of human prompt/response ratings for themselves or scrutinize more detailed statistics, such as direct pairwise win rates between models and confidence interval ranges for those Elo estimates.


{kind=link}