Are you ready to bring more awareness to your brand? Consider becoming a sponsor for The AI Impact Tour. Learn more about the opportunities here.
Scientists at the University of California, Berkeley have developed a novel machine learning (ML) method, termed “reinforcement learning via intervention feedback” (RLIF), that can make it easier to train AI systems for complex environments.
RLIF merges reinforcement learning with interactive imitation learning, two important methods often used in training artificial intelligence systems. RLIF can be useful in settings where a reward signal is not readily available and human feedback is not very precise, which happens often in training AI systems for robotics.
Reinforcement learning and imitation learning
Reinforcement learning is useful in environments where precise reward functions can guide the learning process. It’s particularly effective in optimal control scenarios, gaming and aligning large language models (LLMs) with human preferences, where the goals and rewards are clearly defined. Robotics problems, with their complex objectives and the absence of explicit reward signals, pose a significant challenge for traditional RL methods.
In such intricate settings, engineers often pivot to imitation learning, a branch of supervised learning. This technique bypasses the need for reward signals by training models using demonstrations from humans or other agents. For instance, a human operator might guide a robotic arm in manipulating an object, providing a visual and practical example for the AI to emulate. The agent then treats these human-led demonstrations as training examples.
VB Event
The AI Impact Tour
Connect with the enterprise AI community at VentureBeat’s AI Impact Tour coming to a city near you!
Despite its advantages, imitation learning is not without its pitfalls. A notable issue is the “distribution mismatch problem,” where an agent may face situations outside the scope of its training demonstrations, leading to a refuse in performance. “Interactive imitation learning” mitigates this problem by having experts furnish real-time feedback to refine the agent’s behavior after training. This method involves a human expert monitoring the agent’s policy in action and stepping in with corrective demonstrations whenever the agent strays from the desired behavior.
However, interactive imitation learning hinges on near-optimal interventions, which are not always available. Especially in robotics, human input may not be precise enough for these methods to be fully effective.
Combining reinforcement learning and imitation learning
In their research, the U.C. Berkeley scientists examine a hybrid approach that leverages the strengths of reinforcement learning and interactive imitation learning. Their method, RLIF, is predicated on a simple insight: it’s generally easier to recognize errors than to execute flawless corrections.
This concept is particularly relevant in complex tasks appreciate autonomous driving, where a safety driver’s intervention—such as slamming on the brakes to impede a collision—signals a deviation from desired behavior, but doesn’t necessarily model the optimal response. The RL agent should not learn to imitate the sudden braking action but learn to avoid the situation that caused the driver to brake.
“The decision to intervene during an interactive imitation episode itself can furnish a reward signal for reinforcement learning, allowing us to instantiate RL methods that work under similar but potentially weaker assumptions as interactive imitation methods, learning from human interventions but not assuming that such interventions are optimal,” the researchers explain.
appreciate interactive imitation learning, RLIF trains the agent through a sequence of demonstrations followed by interactive interventions. However, it does not assume that the interventions by human experts are optimal. It merely treats the intervention as a signal that the AI’s policy is about to take a wrong turn and trains the system to avoid the situation that makes the intervention necessary.
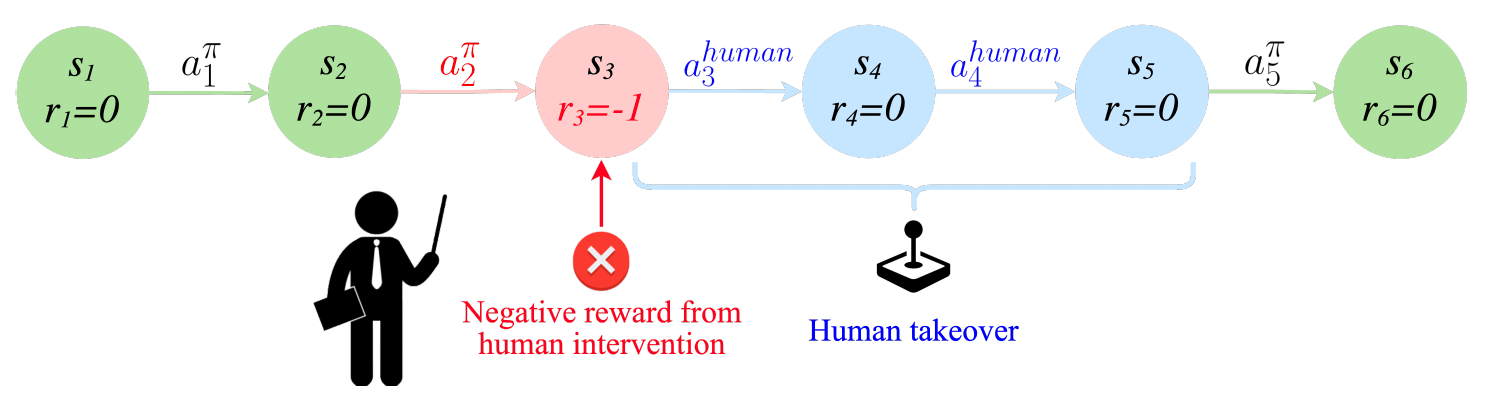
RLIF combines reinforcement learning and intervention signals from human experts (source: arxiv)
“Intuitively we assume that the expert is more likely to intervene when [the trained policy] takes a bad action. This in principle can furnish an RL algorithm with a signal to alter its behavior, as it suggests that the steps leading up to this intervention deviated significantly from optimal behavior,” the researchers reported.
RLIF addresses the limitations inherent in both pure reinforcement learning and interactive imitation learning, including the need for a precise reward function and optimal interventions. This makes it more practical to use it in complex environments.
“Intuitively, we expect it to be less of a burden for experts to only point out which states are undesirable rather than actually act optimally in those states,” the researchers noted.
Testing RLIF
The U.C. Berkeley team put RLIF to the evaluate against DAgger, a widely used interactive imitation learning algorithm. In experiments on simulated environments, RLIF outperformed the best DAgger variants by a factor of two to three times on average. Notably, this performance gap widened to five times in scenarios where the quality of expert interventions was suboptimal.
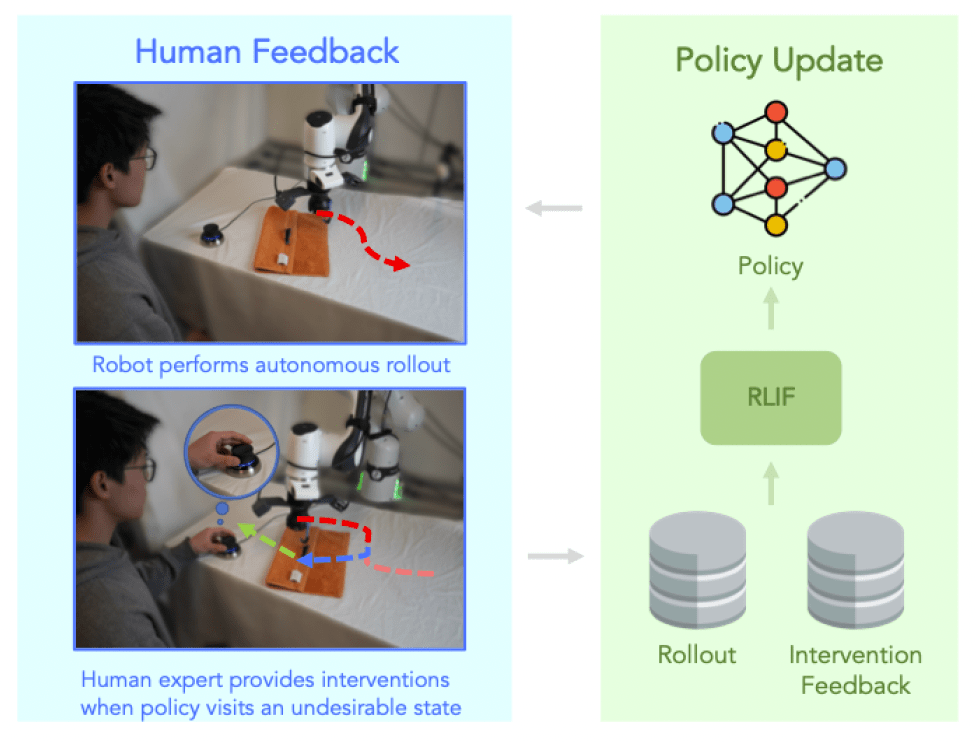
RLIF in action on physical robots (source: arxiv)
The team also tested RLIF in real-world robotic challenges, such as object manipulation and cloth folding with actual human feedback. These tests confirmed that RLIF is also robust and applicable in real-world scenarios.
RLIF has a few challenges, such as significant data requirements and the complexities of online deployment. Certain applications may also not tolerate suboptimal interventions and explicitly necessitate oversight by highly trained experts. However, with its practical use cases, RLIF can become an important tool for training many real-world robotic systems.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. ascertain our Briefings.

