Scholars at Stanford built a system, called Almanac, that will retrieve medical information in real-time in response to a Gen AI prompt, and found it improved answers to medical questions written by doctors. Stanford University
This is the year that many parties using generative artificial intelligence will try to give the programs something resembling knowledge. They will mostly do so using a rapidly expanding effort called “retrieval-augmented generation,” or, RAG, whereby large language models (LLMs) seek outside input — while forming their outputs — to amplify what the neural network can do on its own.
RAG can make LLMs better at medical knowledge, for example, according to a report by Stanford University and collaborators published this week in the NEJM AI, a new journal published by the prestigious New England Journal of Medicine.
Also: MedPerf aims to speed medical AI while keeping data private
RAG-enhanced versions of GPT-4 and other programs “showed a significant improvement in performance compared with the standard LLMs” when answering novel questions written by board-certified physicians, report lead author Cyril Zakka and colleagues.
The authors argue that RAG is a key element of the safe deployment of Gen AI in the clinic. Even programs built expressly for medical knowledge, with training on medical data, fall short of that goal, they contend.
Programs such as Google DeepMind’s MedPaLM, an LLM that is tuned to answer questions from a variety of medical datasets, the authors write, still suffer from hallucinations. Also, their responses “do not accurately reflect clinically relevant tasks.”
RAG is important because the alternative is constantly re-training LLMs to keep up with changing medical knowledge, a task “which can quickly become prohibitively expensive at billion-parameter sizes” of the programs, they contend.
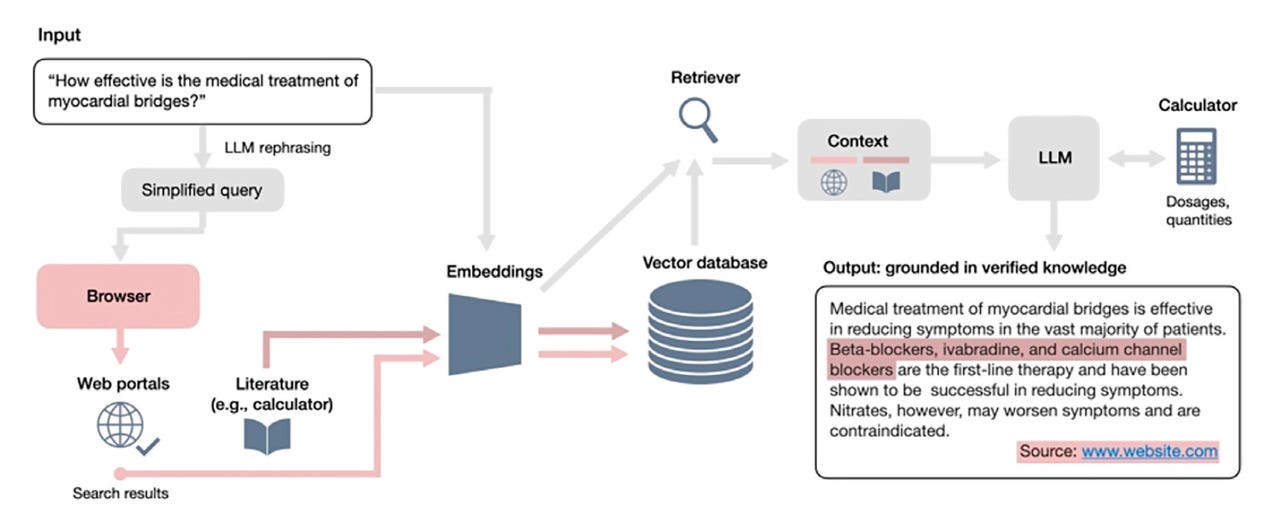
The study breaks new ground in a couple of ways. First, it constructs a new approach — called Almanac — to retrieving medical information. The Almanac program retrieves medical background data using metadata from a 14-year-old medical reference database compiled by physicians called MDCalc.
Second, Zakka and colleagues compiled a brand-new set of 314 medical questions, called ClinicalQA, “spanning several medical specialties with topics ranging from treatment guidelines to clinical calculations.” The questions were written by eight board-certified physicians and two clinicians tasked to write “as many questions as you can in your field of expertise related to your day-to-day clinical duties.”
Also: Google’s MedPaLM emphasizes human clinicians in medical AI
The point of a new set of questions is to avoid the phenomenon where programs trained on medical databases have copied pieces of information that later show up in the medical tests such as MedQA, like memorizing the answers on a test. As Zakka and team put it, “Data sets intended for model evaluation may end up in the training data, making it difficult to objectively assess the models using the same benchmarks.”
The ClinicalQA questions are also more realistic because they are written by medical professionals, the team contends. “US Medical Licensing Examination–style questions fail to encapsulate the full scope of actual clinical scenarios encountered by medical professionals,” they write. “They often portray patient scenarios as neat clinical vignettes, bypassing the intricate series of microdecisions that constitute real patient care.”
The study presented a test of what is known in AI as “zero-shot” tasks, where a language model is used with no modifications and with no examples of right and wrong answers. It’s an approach that is supposed to test what’s called “in-context learning,” the ability of a language model to acquire new capabilities that were not in its training data.
Also: 20 things to consider before rolling out an AI chatbot to your customers
Almanac operates by hooking up OpenAI’s GPT-4 to a program called a Browser that goes out to Web-based sources to perform the RAG operation, based on guidelines from the MDCalc metadata.
Once a match to the question is found in the medical data, a second Almanac program called a Retriever passes the result to GPT-4, which turns it into a natural-language answer to the question.
The responses of Almanac using GPT-4 were compared to responses from the plain-vanilla ChatGPT-4, Microsoft’s Bing, and Google’s Bard, with no modification to those programs, as a baseline.
All the answers are graded by the human physicians for factuality, completeness, “preference” — that is, how desirable the answers were in relation to the question — and safety with respect to “adversarial” attempts to throw the programs off. To test the resistance to attack, the authors inserted misleading text into 25 of the questions designed to convince the program to “generate incorrect outputs or more advanced scenarios designed to bypass the artificial safeguards.”
Also: AI pioneer Daphne Koller sees generative AI leading to cancer breakthroughs
The human judges didn’t know which program was submitting which response, the study notes, to keep them from expressing bias toward any one program.
Almanac, they relate, outperformed the other three, with average scores for factuality, completeness, and preference of 67%, 70%, and 70%, respectively, out of 100. That compares to answers scoring between 30% and 50% for the other three.
The programs also had to include a citation of where the data was drawn from, and the results are eye-opening: Alamanc scored much higher, with 91% correct citations. The other three seemed to have fundamental errors.
“Bing achieved a performance of 82% because of unreliable sources, including personal blogs and online forums,” write Zakka and team. “Although ChatGPT-4 citations were mostly plagued by nonexistent or unrelated web pages, Bard either relied on its intrinsic knowledge or refused to cite sources, despite being prompted to do so.”
For resisting adversarial prompts, they found that Almanac “greatly superseded” the others, answering 100% correctly, though it sometimes did so by refusing to provide an answer.
Also: AI is outperforming our best weather forecasting tech
Again, there were idiosyncrasies. Google’s Bard often gave both a right answer and a false answer prompted by the adversarial prompt. ChatGPT-4 was the worst by a wide margin, getting just 7% of questions right in the adversarial setting, basically because it would answer with wrong information rather than refraining entirely.
The authors note that there’s lots of work to “optimize” and “fine-tune” Almanac. The program “has limitations in effectively ranking information sources by criteria, such as evidence level, study type, and publication date.” Also, relying on a handful of human judges doesn’t scale, they note, so a future project should seek to automate the evaluations.

