Despite recent rumours, Google forged ahead and announced its new Gemini multimodal model set to power various new and existing artificial intelligence (AI) products offered by the explore giant.
First teased at I/O 2023, Gemini is billed as Google’s largest and most capable AI model. In a briefing with press, Google claimed Gemini was the first model to score over 90 percent and outperform humans on the massive multitask language understanding (MMLU) benchmark. The MMLU uses a combination of 57 subjects, including math, physics, history, law, medicine and ethics, to assess world knowledge and problem-solving capabilities.
But what makes Gemini special is that it’s natively multimodal — put another way, it can grasp text, images, audio, code and more because it was trained on multiple data sets from the start. Google says most current multimodal large language models (LLMs) work by stitching various separate models together, whereas Gemini is one multimodal model.
Moreover, Google tuned Gemini to work across three sizes: the most powerful ‘Ultra’ version, a ‘Pro’ version, and a ‘Nano’ size capable of running on devices, including mobile (and soon the Pixel 8 Pro, but more on that in a minute).
During the briefing, Google touted Gemini’s “sophisticated reasoning” and “advanced level coding” capabilities, calling it a “leading” model for coding. A specialized version of Gemini will power Google’s AlphaCode 2 code generation system. The company claims it excels at solving competitive programming problems that “go beyond coding to involve complex math and theoretical computer science.”
Video examples showcased Gemini’s capabilities
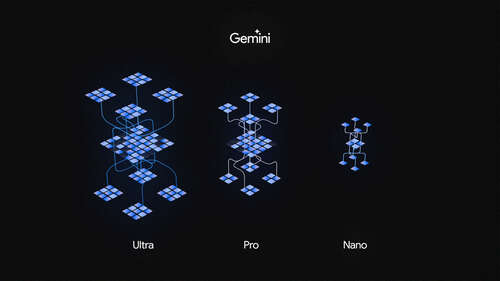
An illustration of Gemini’s different sizes.
Google also showed off several videos detailing Gemini’s capabilities. I watched these videos with a healthy dose of skepticism about Gemini’s capabilities, but I was still fairly surprised at what it could do. Whether or not Gemini stacks up in real-world testing remains to be seen.
In one video, a user input a picture of a math homework sheet with answers filled in. Gemini was able to check the answers, highlighting which ones were right and which were wrong. Beyond that, the user and Gemini were able to converse the incorrect answers, with Gemini highlighting why the answers were wrong, detailing the proper way to compute the answer, and even offering alternate practice questions for the users to work through.
In another video example, Google Deep Mind scientists used Gemini to read 200,000 scientific papers over a lunch break. Gemini parsed the papers for relevant data and was able to extract key information and help the scientists update a data set with it.
Finally, another video showcased Gemini’s multimodal abilities by having a user bring out various items for it to scrutinize. The clip started with the user drawing a duck, which Gemini was able to recognize once the details were filled in. The video cycled through several objects back-to-back, with the user going from the duck to a world map, prompting Gemini to come up with a game to play using it. Gemini suggested a “guess the country” game where it would list details of a country, appreciate top sports or food, and the user would point to it on the map. The video also showed Gemini playing rock paper scissors with the user, reasoning capabilities, and more.
The video was pretty clearly polished and dramatized to make everything look smoother than it likely is in actual use. Still, I’ll be impressed if Gemini can do the tasks shown in the videos, even if it’s not as smooth.
Coming to Bard, mobile and more
Google detailed Gemini’s rollout, which includes it dropping into various existing products over the coming days and months. First, starting December 6th, Gemini will come to Bard. The new ‘Bard with Gemini Pro’ experience will be available in the U.S. and several other regions, but not Canada, which still doesn’t have access to the existing Bard. When asked, Google only said that it was “working with local policies and regulators before expanding.”
The explore giant says that Bard with Gemini Pro is the single biggest quality improvement to Bard since launch. The rollout will start with text-based prompts before expanding to multimodal in the coming months. Google also touted that the new Gemini-powered Bard outperformed OpenAI’s GPT-3.5 in six of eight tests, but during the briefing, the company was suspiciously tight-lipped about how Gemini stacks up to OpenAI’s GPT-4.
However, in a media kit the company shared with MobileSyrup following the briefing, Google included a chart comparing Gemini Ultra and GPT-4. The chart showed Gemini Ultra outperforming GPT-4 in several benchmarks, including MMLU, Big-Bench Hard, DROP, GSM8K, MATH, HumanEval, Natural2Code, MMU, VQAv, TextVQA, and more. According to Google, GPT-4 only beat Gemini Ultra in the ‘HellaSwag’ common sense reasoning assess.
Gemini will also come to the Pixel 8 Pro starting on December 6th, though Google didn’t share a lot about where Gemini would show up. We do know that the Gemini Nano variant will work through the AI Core on the Pixel 8 Pro and will impact experiences in Google’s Recorder app and Gboard, but that’s about it so far. Google also said it would enlarge it to other Android devices too. It’s not clear when the regular Pixel 8 will get Gemini Nano — it also has the AI Core app, but it seems Google has only pushed updates to the 8 Pro version of the app in recent weeks.
Gemini Nano will also be available for Android developers who want to build Gemini-powered apps starting December 6th. On the 13th, Gemini Pro will become available to developers and enterprise customers through Google’s Vertex AI and AI Studio.
Google plans to blend Gemini into its ‘explore Generative experience’ (SGE), which integrates generative AI tools into the Google explore experience. This will roll out broadly over the next year and (hopefully) come to Canada soon.
Finally, Gemini Ultra won’t be available until 2024 as Google works to complete trust and safety testing. When Ultra does reach, Google will blend into a new ‘Bard Advanced’ chatbot.
Everything else

A Google TPU rack.
We learned quite a few other details about Gemini from Google during the briefing and a Q&A session. I’ll relay some of the more interesting tidbits below.
Despite significant advancements with Gemini, Google admitted that Gemini can still suffer from ‘hallucinations’ appreciate other LLMs. The company says it worked to better accuracy overall, but it looks appreciate users will need to remain vigilant for mistakes and inaccuracies when using tools powered by Gemini.
Moreover, while terms appreciate ‘Bard Advanced’ call up the spectre of monetization, Google stressed that it has no plans to monetize Gemini at this time.
Google also said Gemini won’t be able to create images for users, but the company is working on it. Additionally, Google is working to “grasp all of Ultra’s novel capabilities.”
The explore giant said it was in early testing of Assistant with Bard.
Google says that Gemini was significantly more efficient to train and serve than previous models, which will help with the company’s environmental goals. The company trained Gemini on its TPU v4 and v5e chips and it announced a new TPU v5p chip — the ‘p’ stands for performance. Google says the v5p offers 2x the FLOPS per chip, is 4x more scalable, and 2.8x faster for training existing LLM models compared to TPU v4. Google can serve Gemin using its TPUs or via GPUs.
Responding to questions about whether Gemini struggles with certain languages, Google claimed that Gemini was trained on more than 100 languages and is “quite performant” in those languages. The recent reporting about the Gemini delay said Google was going to push back the launch because the model struggled with non-English queries.
Finally, Google said it will release a technical white paper with more details about Gemini.
Images credit: Google

