Humans use expressive behaviors to communicate goals and intents. We nod to acknowledge the presence of a coworker, shake our heads to convey a negative response, or use simple utterances like “excuse me” to ask others to make way. Mobile robots that want to share their environments with humans should be able to show such behavior. This remains one of the important challenges of robotics, and current solutions are rigid and limited in scope.
In a new study, researchers at the University of Toronto, Google DeepMind and Hoku Labs propose a solution that uses the vast social context available in large language models (LLM) to create expressive behaviors for robots. Called GenEM, the technique uses various prompting methods to understand the context of the environment and use the robot’s capabilities to mimic expressive behaviors.
GenEM has proven to be more versatile than existing methods and can adapt to human feedback and different types of robots.
Expressive behaviors
The traditional approach to creating expressive behavior in robots is to use rule- or template-based systems, where a designer provides a formalized set of conditions and the corresponding robot behavior in these systems. The main problem with rule-based systems is the manual effort required for each type of robot and environment. Moreover, the resulting system is rigid in behavior and requires reprogramming to adapt to novel situations, new modalities or varying human preferences.
VB Event
The AI Impact Tour – NYC
We’ll be in New York on February 29 in partnership with Microsoft to discuss how to balance risks and rewards of AI applications. Request an invite to the exclusive event below.
More recently, researchers have experimented with data-driven approaches for creating expressive behavior, which are more flexible and can adapt to variations. Some of these approaches use classic machine learning models to learn interaction logic through data gathered from the robots. Others use generative models. While better than rule-based systems, data-driven systems also have shortcomings such as the need for specialized datasets for each type of robot and social interaction where a behavior is used.
The main premise of the new technique is to use the rich knowledge embedded in LLMs to dynamically generate expressive behavior without the need for training machine learning models or creating a long list of rules. For example, LLMs can tell you that it is polite to make eye contact when greeting someone or to nod to acknowledge their presence or command.
“Our key insight is to tap into the rich social context available from LLMs to generate adaptable and composable expressive behavior,” the researchers write.
Generative Expressive Motion (GenEM)
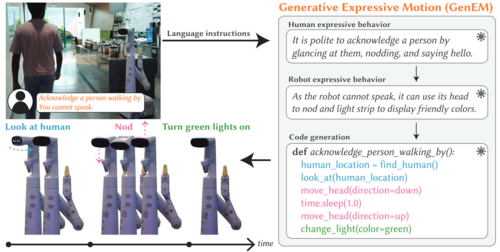
Generative Expressive Motion (GenEM), the technique proposed by DeepMind, uses a sequence of LLM agents to autonomously generate expressive robot behaviors from natural language instructions. Each agent plays a distinct role in reasoning over the social context and mapping the desired expressive behavior to API calls for the robot.
“GenEM can produce multimodal behaviors that utilize the robot’s available affordances (e.g., speech, body movement, and other visual features such as light strips) to effectively express the robot’s intent,” the researchers write. “One of the key benefits of GenEM is that it responds to live human feedback – adapting to iterative corrections and generating new expressive behaviors by composing the existing ones.”
The GenEM pipeline starts with an instruction written in natural language. The input can be an expressive behavior, such as “Nod your head,” or it can describe a social context where the robot must follow social norms, such as “A person walking by waves at you.”
In the first step, the LLM uses chain-of-thought reasoning to describe how a human would respond in such a situation. Next, another LLM agent translates the human expressive motion into a step-by-step procedure based on the robot’s functions. For example, it might tell the robot to nod using its head’s pan and tilt capabilities or mimic a smile by displaying a pre-programmed light pattern on its front display.
Finally, another agent maps the step-by-step procedure for the expressive robot motion to executable code based on the robot’s API commands. As an optional step, GenEM can take in human feedback and use an LLM to update the generated expressive behavior.
None of these steps require training the LLMs and are based on prompt-engineering techniques that only need to be adjusted to the affordances and API specifications of the robot.
Testing GenEM
The researchers compared behaviors generated on a mobile robot using two variations of GenEM—with and without user feedback—against a set of scripted behaviors designed by a professional character animator.
They used OpenAI’s GPT-4 as the LLM for reasoning about the context and generating expressive behavior. They surveyed dozens of users on the results. Their findings show that in general, users find behaviors generated by GenEM to be just as understandable as those carefully scripted by a professional animator. They also found that the modular and multi-step approach used in GenEM is much better than using a single LLM to directly translate instructions to robot behavior.
More importantly, thanks to its prompt-based structure GenEM is agnostic to the type of robot it is applied to without the need to train the model on specialized datasets. Finally, GenEM can leverage the reasoning capabilities of LLMs to use a simple set of robotic actions to compose complicated expressive behaviors.
“Our framework can quickly produce expressive behaviors by way of in-context learning and few-shot prompting. This reduces the need for curated datasets to generate specific robot behaviors or carefully crafted rules as in prior work,” the researchers write.
GenEM is still in its early stages and needs to be further investigated. For example, in its current iteration, it has only been tested in scenarios where the robot and humans only interact once. It has also been applied to limited action spaces and can be explored on robots that have a richer set of primitive actions. Large language models can have promising results in all these areas.
“We believe our approach presents a flexible framework for generating adaptable and composable expressive motion through the power of large language models,” the researchers write.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.

