Meta’s AI chief Yann LeCun has been a long-time proponent of machine learning (ML) systems that can learn to explore and understand the world on their own, with little or no guidance from humans. Meta’s latest ML model, V-JEPA, is the company’s next step toward realizing this vision.
The goal of V-JEPA, which stands for Video Joint Embedding Predictive Architecture, is to mimic the abilities of humans and animals to predict and anticipate how objects interact with each other. It does this by learning abstract representations from raw video footage.
While much of the industry is competing over generative AI, V-JEPA shows the promise of what can be the next generation of non-generative models in real-world applications.
How V-JEPA works
If you see a video segment of a ball flying toward a wall, you would expect the next frames to show the ball continuing down its trajectory. When it reaches the wall, you would expect it to bounce back and reverse its direction. If it is passing by a mirror, you would expect its reflection to be projected on the window. You learn these basic rules simply through observing the world around you early in life, even before you learn to talk or take instructions from your parents. At the same time, you learn to do this efficiently, without the need to predict very granular details about the scene.
VB Event
The AI Impact Tour – NYC
We’ll be in New York on February 29 in partnership with Microsoft to discuss how to balance risks and rewards of AI applications. Request an invite to the exclusive event below.
V-JEPA uses the same rule of learning through observations, referred to as “self-supervised learning,” which means that V-JEPA does not need human-labeled data. During training, it is provided with a video segment, parts of which are masked out. The model tries to predict the contents of the missing patches without filling in every pixel. Instead, what it learns is a smaller set of latent features that define how different elements in the scene interact with each other. It then compares its predictions with the actual content of the video to calculate the loss and adjust its parameters.
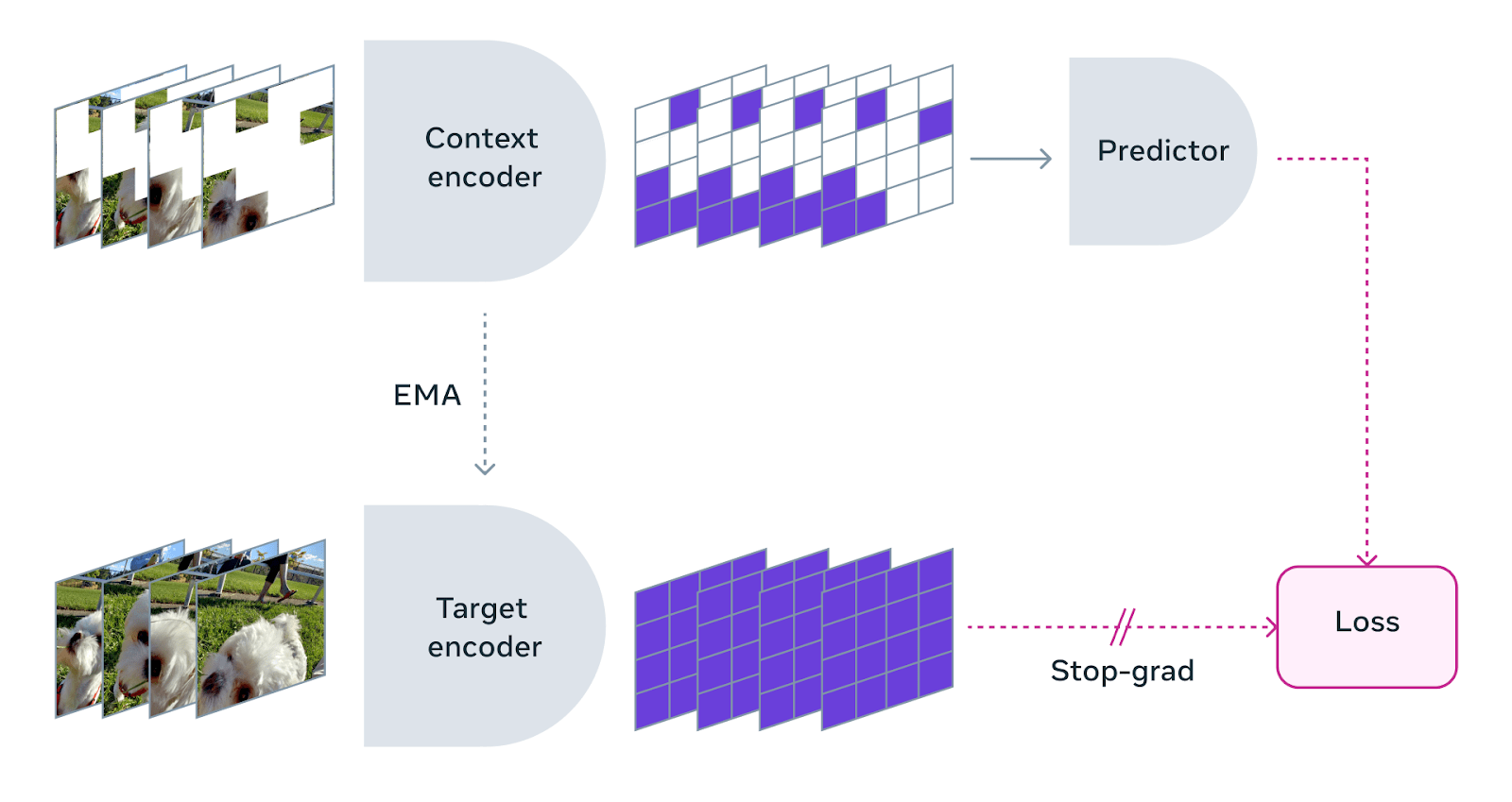
The focus on latent representations makes the models much more stable and sample-efficient. Instead of focusing on one task, V-JEPA was trained on a range of videos that represent the diversity of the world. The research team designed its masking strategy to force the model to learn the deep relations of objects instead of spurious shortcuts that do not translate well to the real world.
After being trained on many videos, V-JEPA learns a physical world model that excels at detecting and understanding highly detailed interactions between objects. JEPA was first proposed by LeCun in 2022. Since then, the architecture has gone through several improvements. V-JEPA is the successor to I-JEPA, which Meta released last year. While I-JEPA was focused on images, V-JEPA learns from videos, which have the advantage of showing how the world changes through time and enables the model to learn more consistent representations.
V-JEPA in action
V-JEPA is a foundation model, which means it is a general-purpose system that must be configured for a specific task. However, unlike the general trend in ML models, you do not need to fine-tune the V-JEPA model itself and modify its parameters. Instead, you can train a lightweight deep-learning model with a small set of labeled examples to map the representations from V-JEPA to a downstream task.
This enables you to use the same V-JEPA model as the input for several other models for image classification, action classification, and spatiotemporal action detection tasks. This kind of architecture is compute- and resource-efficient and can be managed much more easily.
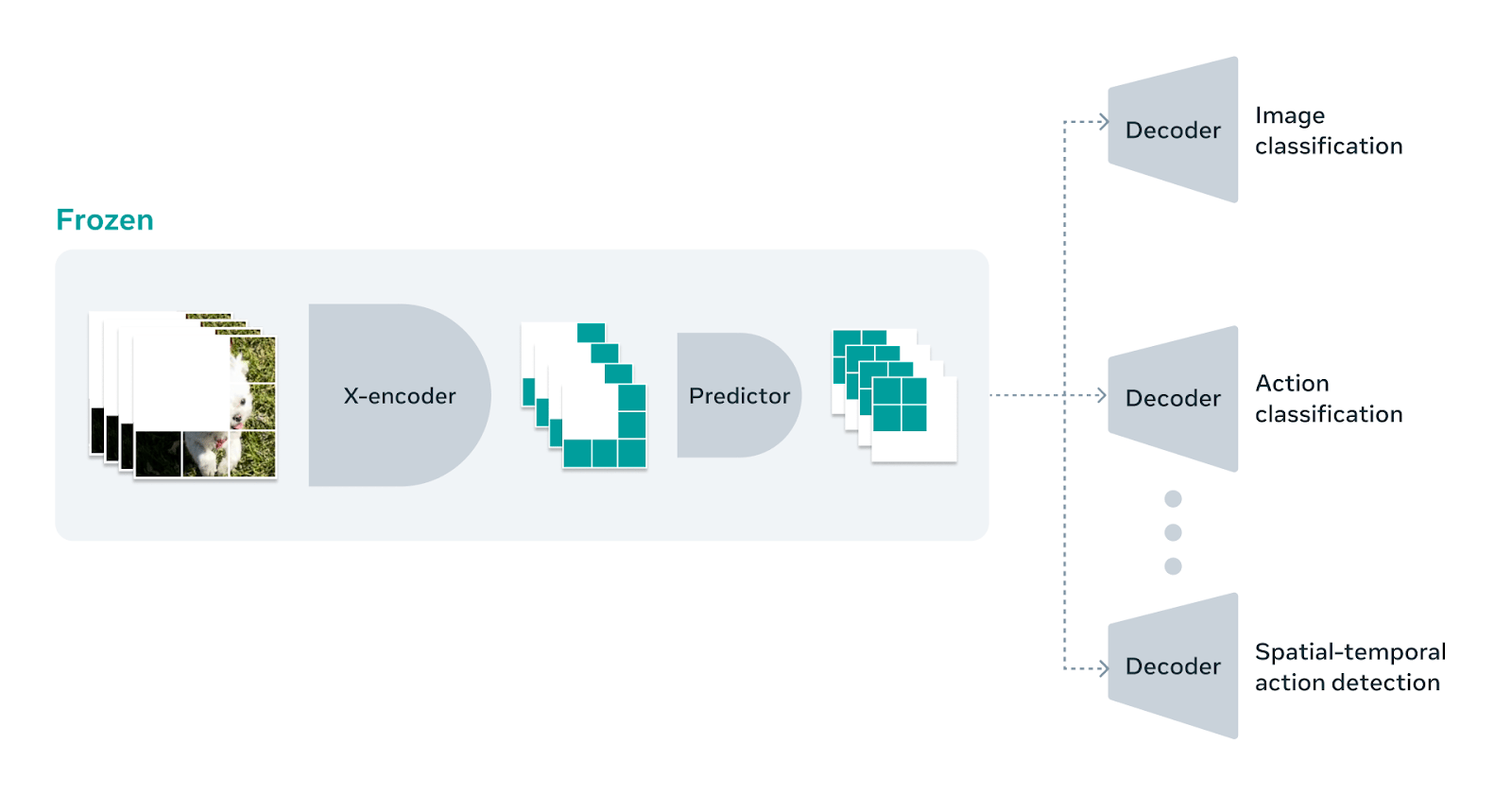
This is especially useful for applications in areas such as robotics and self-driving cars, where the models need to understand and reason about their environment, and plan their actions based on a realistic world model.
“V-JEPA is a step toward a more grounded understanding of the world so machines can achieve more generalized reasoning and planning,” says LeCun.
While the JEPA architecture has come a long way, it still has a lot of room for improvement. V-JEPA currently outperforms other methods in reasoning over videos for several seconds. The next challenge for Meta’s research team will be to expand the model’s time horizon. The researchers also plan to narrow the gap between JEPA and natural intelligence by trying out models that learn multimodal representations. Meta has released the model under a Creative Commons NonCommercial license so that other researchers can explore how to use and improve it.
In a talk in 2020, LeCun said that if intelligence is a cake, the bulk is self-supervised learning, the icing is supervised learning, and the cherry on top is reinforcement learning (RL).”
We have reached the bulk of the AI cake. But in many ways, we might be still scratching the surface of what is possible.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.

