Key Takeaways
- Large Language Models (LLMs) power AI chatbots like ChatGPT and Google Bard, allowing them to process requests and provide responses.
- LLMs rely on pre-training on vast amounts of data and a set of parameters to determine how they produce text and respond to prompts.
- LLMs, such as AI chatbots, have diverse applications, including providing facts, translating text, generating ideas, and enhancing search engine results.
While AI chatbots like ChatGPT are now incredibly popular, many of us still don’t understand how they work. These chatbots are powered by LLMs, and it’s this technology that holds a lot of potential for the future. So, what is an LLM, and how does it allow AI to hold conversations with humans?
What Is an LLM?
The term “LLM” is short for Large Language Model. A large language model provides the framework for AI chatbots like ChatGPT and Google Bard, allowing them to process requests and provide responses.
The concept of conversational computers was around long before the first example of this technology was put into practice. Back in the 1930s, the idea of a conversational computer arose, but remained entirely theoretical. Decades later, in 1967, the world’s first chatbot, ELIZA, was created. Developed by MIT’s Joseph Weizenbaum, ELIZA was a text-based program that used a tactic known as “pattern matching” to talk to users, and used a stock of conversational scripts from which it could pull responses.
The New Jersey Institute of Technology still provides a web-based version of ELIZA that can be interacted with today.
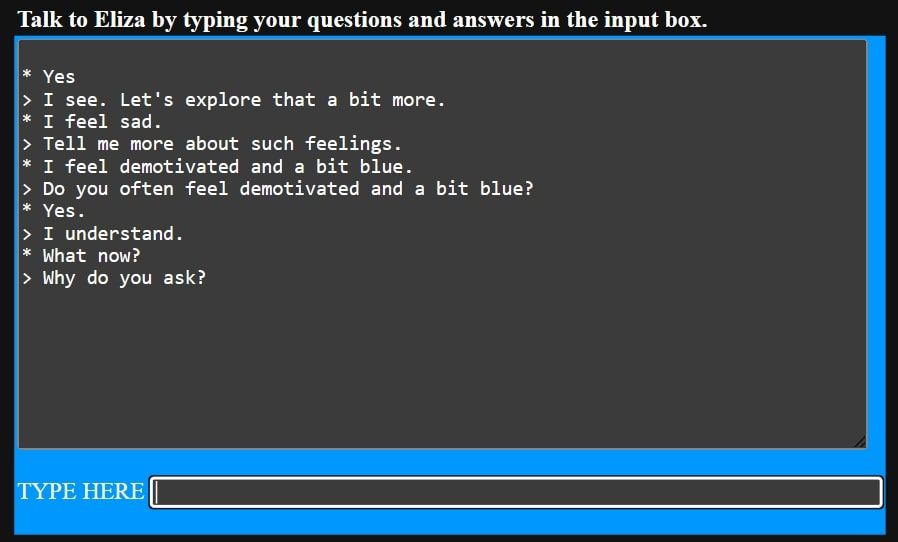
As you can see, ELIZA isn’t great at interpreting language and providing useful information. But as a 1960s invention, this chatbot was groundbreaking, as it was able to respond to prompts in a relatively human way, while also having the ability to continue a conversation. Above, we told ELIZA that we were sad, and it was able to ask us to tell it more, and question how long we’d been feeling that way.
While ELIZA was an innovative invention, it wasn’t an LLM. In fact, it took another 47 years for a technology close to today’s LLMs to be achieved.
In 2013, an algorithm known as word2vec became the LLM’s most recent ancestor. Word2vec is a natural language processing (NLP) algorithm used to take one word and convert it into an array of numbers known as a vector. This may seem basic on the surface, but what was amazing about word2vec is that it could create semantic connections between different words after vectorizing them. This ability to create association between words was a huge step towards modern LLMs.
While many associate OpenAI and its chatbot, ChatGPT, with having fathered LLMs, this isn’t the case. The first LLM breakthrough was made by Google in 2017 with its Bidirectional Encoder Representations from Transformers (BERT). BERT was developed in order to improve Google’s search engine algorithm, so that user searches can be better interpreted, therefore providing improved search results.
Prior to BERT’s release, several Google researchers wrote and published a paper titled Attention Is All You Need. This paper set the stage for transformers, as it introduced this technology to the world. We’ll get a little more into how transformers work later on.
In 2022, LLMs hit the mainstream when AI chatbots like ChatGPT, Claude, and Google Bard became all the rage. The release of OpenAI’s ChatGPT-3.5 was the catalyst for this new trend, as the chatbot offered a very impressive conversational AI tool that could very effectively process human language. Since then, LLMs have become a hot topic of conversation, and more LLM-based tools are being released every week.
So, what’s behind this impressive technology?
How Do LLMs Work?
A crucial element that a lot of popular LLMs need is pre-training. Before an LLM is put to work processing language, it needs to be trained on a vast amount of data, as well as a set of parameters.
Take OpenAI’s GPT-3.5, for example. This LLM was trained on all kinds of text-based data, including books, articles, academic journals, web pages, online posts, and more. On top of this, billions of variables, known as “parameters”, are set in place to determine how GPT-3.5 produces text and responds to prompts. GPT-3.5’s training also involved two other aspects, known as “reinforcement” and “next-word prediction.”
However, other kinds of LLMs go through a different preliminary process, such as multimodal and fine-tuning. OpenAI’s DALL-E, for instance, is used to generate images based on prompts, and uses a multimodal approach to take a text-based response, and provide a pixel-based image in return (i.e. one form of input media is converted to another form of output media).
Google’s BERT, on the other hand, goes through a preliminary process known as fine-tuning, which is less focused on producing natural language responses, and more focused on responding to more specific tasks like text classification and question answering (which improves the quality of search results).
LLMs also rely on a neural network to function, and the most common type used is known as a transformer. Below is a basic diagram depicting the process of a transformer, but we’ll delve into more detail to better understand how it works.
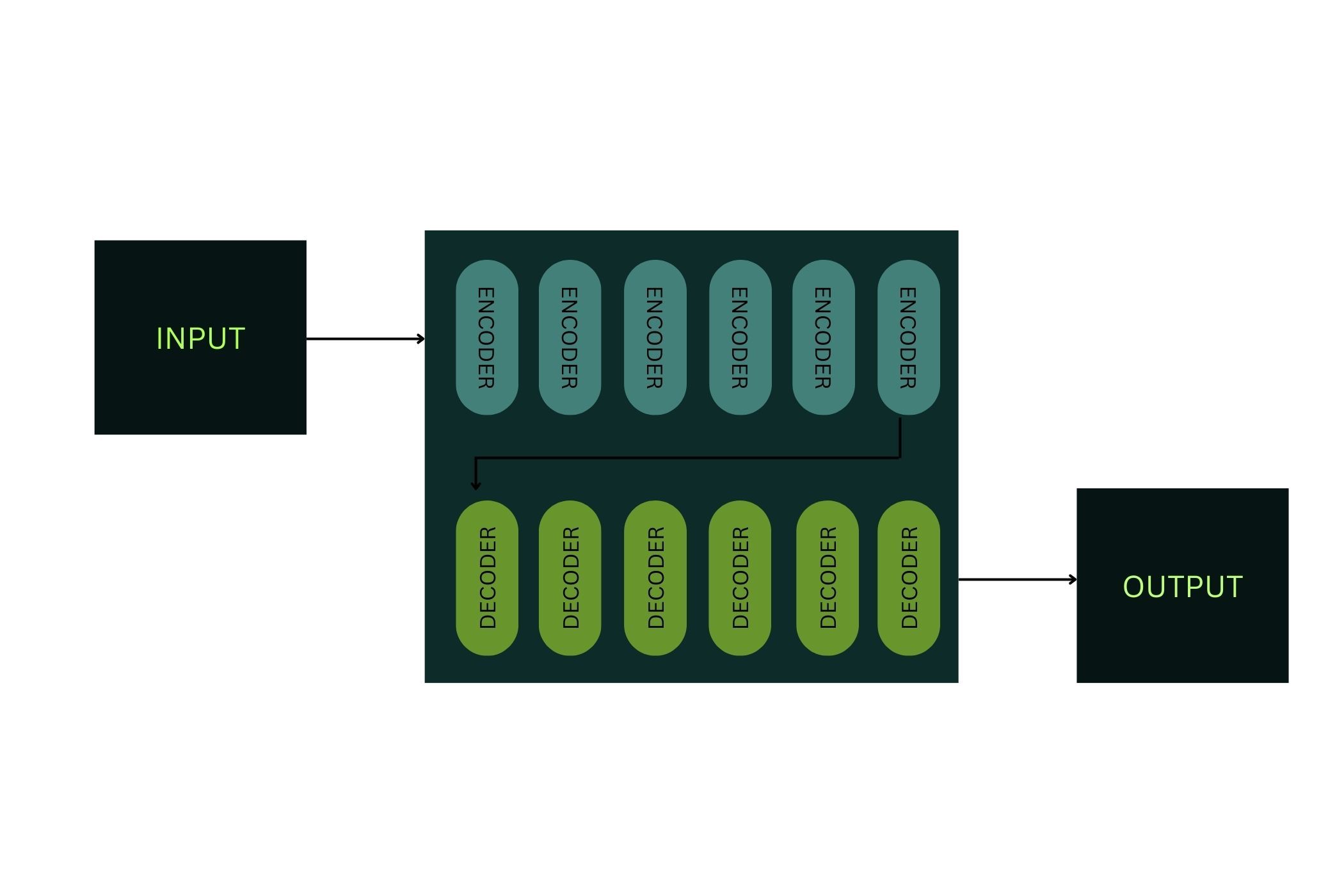
Transformer neural networks play a crucial role in allowing the system to predict what words are coming next, and the importance and context of each word in a given sentence. Within the transformer model, there is an encoder step and a decoder step, each of which consists of multiple layers. First, text-based data reaches the encoder, and is then converted to numbers.
These individual numerical units are also known as tokens, which is why you may hear the term “token limit” when AI chatbots are being discussed.
These tokens are then categorized by the transformer, creating a map of the significance of each token, and how one token relates to another. In short, the transformer uses the numerical map it’s created to understand the context around the data, and how one token is connected to another. This process is also known as transformer self-attention, or multi-head attention.
Self-attention involves the transformer performing multiple calculations at once while comparing various input tokens to each other. From this, an output attention score is calculated for each token, or word. The more attention a word gets, the more heavily it is considered when creating an output (or response).
Now, it’s time to decode the numerical data into a text-based response. In this process, the encoded input tokens are converted to text-based output tokens, which forms the LLM’s reply to a prompt.
Without the transformer, the context, nuances, and relationship between words could not be determined, rendering the LLM effectively useless, as its responses would be ineffective or even nonsensical.
Where Are LLMs Used?

There are a few major LLMs out there today, including Claude, LaMDA, LLaMA, Cohere, GPT-3.5, and GPT-4. A lot of these LLMs were developed by well-known tech giants, such as Google and Meta, though others are the product of AI-focused companies like OpenAI and Anthropic.
The most well-known examples of LLMs in action are AI chatbots, such as Bard, ChatGPT, Claude, and Bing Chat. These nifty tools began rising in popularity in late 2022, after OpenAI released GPT-3.5. Since then, the application scope of LLMs has widened vastly, but AI chatbots remain very popular.
This is because AI chatbots can offer users a myriad of services. You can ask these tools to provide facts, translate text, generate ideas, tell jokes, write poems and songs, and much more. The versatility of AI chatbots makes them useful in all walks of life, and companies are continuously working on improving their AI chatbots for an even better experience.
But things don’t stop with AI chatbots. Some very well-known LLMs are used outside of chatbot environments. For instance, Google’s BERT is used to enhance the quality of search engine results, and was around years before chatbot-based LLMs became popular.
Given how new LLM technology is, there are also a lot of prospective uses that may be applied in the future. LLMs can prove useful in the healthcare industry, specifically in research analysis, patient scenario simulations, discharge summaries, and medical queries. However, the most recent iterations of LLMs still struggle with factual inaccuracies, training data limitations, and AI hallucinations, so they may not yet be suited for medical use.
LLMs Are an Exciting New Technology
LLMs are still in their infancy, having only been officially invented in 2017. But the potential of this language processing method is truly astounding, with LLM-based tools already offering capabilities that were once impossible for computers. In the near future, we may see LLMs advance even further, with more and more industries adopting the technology.

